
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 이처럼사소한것들
- 웹스크래핑
- network
- 정보보안
- XDR
- 클레어키건
- 통합보안솔루션
- dhcp
- CBI면접
- mdr
- 방화벽
- 롯데모의면접
- anti-virus
- Soar
- 네트워크
- SSLVPN
- opencv를이용한이미지자르기
- 이미지크롤링
- 보안
- 파이썬
- rayframework
- 보안관제
- EDR
- JBLY
- 롯데인재개발원
- ips/ids
- 크롤링
- 네트워크보안
- 롯데그룹모의면접
- 보안솔루션
- Today
- Total
아리아 날다
[Python Crawling] 쇼핑몰 크롤링시 뭉쳐있는 이미지 OpenCV로 crop해서 저장하기 본문
| 들어가며 |
안녕하세요, 인생의 고수가 되고 싶은 아리아입니다.
오늘은 지난 게시글에서 말씀 드렸던 이미지 데이터를 크롤링한 후 저장하는 기능을 구현하면서 만났던 문제상황과 해결과정에 대해서 작성해보려고 합니다. 데이터 수집이 끝나면 TensorFlow를 이용해 이미지를 카테고리별로 AI가 구분할 수 있도록 학습시키는 작업을 할 예정입니다. 효과적인 AI학습을 위해선 최대한 많은 양의 이미지 데이터를 다운로드 받아야 하고, 경우에 따라선 AI가 제대로 인식할 수 있도록 이미지를 가공하는 작업도 필요합니다. 그럼 이제부터 이미지를 다루는데 어떤 문제가 있었고, 어떻게 해결했는지에 대해서 알아보겠습니다.
| 문제 상황 |
⚠️ 하나의 이미지에 여러장의 이미지가 들어있다.
더베를린과 포르테나 사이트의 경우 특정 태그의 클래스 안에 위치한 모든 img태그의 src속성을 전부 크롤링하는 방식으로 구현했습니다. img태그 안에 있는 src속성이 개별적인 이미지 url을 명시하고 있기 때문에 url데이터를 가져와 로컬에 저장하는 방식으로 구현이 가능했습니다. 하지만 모어체리 사이트는 아래 사진처럼 여러 개의 상품 사진이 하나의 파일에 들어있는 구조로 저장되어 있습니다. 필요한 데이터는 각각의 이미지 파일이기 때문에 이미지를 분리하는 작업이 필요했습니다.

| 해결 과정 |
✅ 이미지 가공을 위해 Open CV 라이브러리 사용, 어떤 방식으로 이미지를 자를 것인가?
[사진 1] 처럼 사진이 이어져 있는 1개의 파일을 8개의 이미지로 나눈 후 로컬에 저장하기 위해서 Open CV 라이브러리를 이용해 작업했습니다. Open CV(Open Source Computer Vision Library)는 영상 처리 및 컴퓨터 비전을 위한 오픈소스 라이브러리로, C++, Python, Java 등 다양한 언어로 사용할 수 있으며, 실시간 이미지 프로세싱과 컴퓨터 비전 애플리케이션을 개발하는데 사용됩니다. 여기서 컴퓨터 비전은 컴퓨터가 이미지나 비디오에서 정보를 추출하고 해석하는 분야를 말합니다. 컴퓨터 비전은 자율 주행, 보안 시스템, 의료 영상 분석, 로봇 및 드론의 자율 제어, 영상 검색 및 분류, 게임 그래픽, 가상 및 혼합 현실 등에서 사용됩니다.

이미지, 영상 처리 관련 지식이 전무했기 때문에 Open CV 라이브러리 사용 전에 조언을 구했고, 브레인 스토밍을 하는 과정에서 아이디어가 떠올랐습니다.
Open CV로 이미지간 색상차이를 감지해서 잘라야 하는가?

위 [사진2]를 확대해보면 하얀색 실선 여백으로 각각의 이미지가 구분되어있는 경우가 있어 그 부분을 감지해서 자르는 방식을 고려해보았습니다. 하지만 몇 개의 상품 사진은 사진 편집을 하다 생긴 오류인지 사진이 살짝 겹쳐져 있어 여백이 없는 경우도 있었습니다. 따라서 색상 차이를 감지하는 방식은 한계가 있었습니다.
사진 개수가 다 다르다. 어떤 부분을 기준으로 잘라야 하는가?
위 [사진 1]의 경우 총 8개의 디테일 사진이 있지만 상품에 따라 더 많은 경우도 있고, 더 적은 경우도 있습니다. 따라서 사진 개수를 기준으로 자르는 것이 아니라 이미지 크기를 기준으로 잘라야 합니다. 해당 사진을 다운받아 크기를 재보니 맨 위에 위치한 사진은 여백을 포함해 800x1000이고, 그 아래 나머지 사진들은 800x800으로 이미지 크기가 동일했습니다.
| OpenCV를 이용한 이미지 자르기 |
1️⃣ 이진 데이터를 numpy 배열로 변환합니다.
img_url = main_url + clothes_img_tag['ec-data-src']
with urllib.request.urlopen(img_url) as response:
data = response.read()
img = np.asarray(bytearray(data), dtype=np.uint8)
img_cropper(img, item_type)urllib.request.urlopen() 함수를 사용하여 가져온 이진 데이터 'data'를 bytearray() 함수를 사용하여 바이트 배열로 변환한 후, np.asarray() 함수를 사용하여 바이트 배열을 numpy 배열로 변환합니다. 위 과정을 통해 이미지 데이터를 numpy배열로 표현할 수 있게 됩니다. 이 과정에서 dtype=np.uint8 매개변수를 사용하여 데이터 타입을 8비트 부호 없는 정수형으로 설정하는 이유는 이미지 데이터가 일반적으로 8비트 부호 없는 정수형으로 표현되기 때문입니다.
numpy는 Python이 수학적 연산을 효과적으로 할 수 있도록 다양한 기능을 제공하는 파이썬 라이브러리입니다. numpy 패키지의 중심은 다차원배열객체(ndarray, N-dimensional array)입니다. 이는 같은 데이터형의 n차원 배열을 캡슐화하고 컴파일된 코드를 실행하며 수학적 퍼포먼스를 실현합니다.
따라서 이진 데이터를 numpy 배열로 변환하는 과정은 이미지 처리를 위해 필수적인 과정입니다. 이를 통해 이미지를 numpy 배열로 변환하고, 다양한 이미지 처리 알고리즘을 적용할 수 있습니다.
2️⃣ 이미지 파일을 디코딩한 후 지정한 크기로 자릅니다.
def img_cropper(img, item_type):
# 이미지 파일을 불러옵니다.
image = cv2.imdecode(img, cv2.IMREAD_COLOR)
# 첫 번째 이미지를 800x1000으로 자릅니다.
first_crop = image[:1000, :800].copy()
md5hash = hashlib.md5(first_crop).hexdigest() + ".jpg"
cv2.imwrite(path_folder_outwear + md5hash, first_crop)
# 이후 이미지들을 800x800으로 자릅니다.
num_crops = (image.shape[0] - 1000) // 800
crop_positions = [(i * 800 + 1000, (i + 1) * 800 + 1000) for i in range(num_crops)]
if (image.shape[0] - 1000) % 800 != 0:
crop_positions.append((num_crops * 800 + 1000, image.shape[0]))cv2.imdecode() 함수를 사용하여 numpy 배열로 전달된 이미지 데이터를 이미지 파일 형식으로 디코딩합니다. 이때 이미지 파일 형식은 IMREAD_COLOR를 사용하여 컬러 이미지로 읽어들입니다. 그후 맨 위에 있는 이미지는 800*1000 사이즈로 자른 후 지정된 폴더에 저장하고, 아래 이미지들은 800*800으로 자릅니다.

cv2.imread() 함수는 첫 번째 인자로 이미지 파일의 경로와 파일 이름을 받기 때문에 로컬에 저장된 이미지 파일이 아닌 img변수가 전달되면 위와 같은 에러가 뜨는 것을 확인 할 수 있습니다. 따라서 HTTP 요청을 통해 받아온 JPEG파일 데이터를 읽어들일 때는 cv2.imdecode() 함수를 사용해야 합니다. 만약 로컬 디렉토리에 저장된 이미지 파일을 읽어들이는 코드를 구현하고 싶다면 cv2.imread() 함수를 사용할 수 있습니다.
3️⃣ 중앙에 정렬된 이미지만 자른 후 해당 카테고리 폴더에 저장합니다.
height, width = crop.shape[:2]
if height > width:
diff = height - width
crop = crop[:, diff // 2:width + diff // 2]
elif width > height:
diff = width - height
crop = crop[diff // 2:height + diff // 2, :]
crop = np.ascontiguousarray(crop)
md5hash_2 = hashlib.md5(crop).hexdigest() + ".jpg"
if not crop.any():
continue
if item_type == product_types.OUTWEAR.name:
cv2.imwrite(path_folder_outwear + md5hash_2, crop)
위 코드는 높이와 너비를 비교해 중앙에 정렬된 이미지만 자른 후 원하는 폴더에 저장하는 코드입니다. crop 변수가 NumPy 배열인 경우 np.ascontiguousarray() 함수를 사용하여 해당 배열의 데이터를 연속된 메모리 공간에 복사하여 성능을 최적화하고, 중복된 이미지는 저장하지 않도록 하기 위해서 md5 해시값으로 이미지 데이터를 처리했습니다.
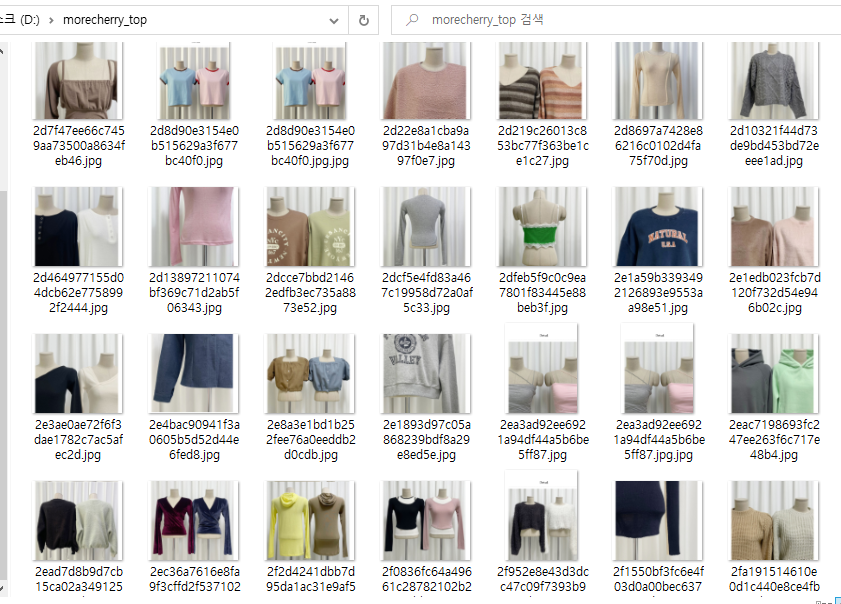
그 결과 이렇게 깔끔하게 이미지가 잘리고 지정한 로컬 폴더에 저장된 것을 확인 할 수 있었습니다. 자세한 코드는 여기에서 확인하실 수 있습니다😸
| 마무리하며 |
OpenCV는 C++로 구현되어 있으며 실시간 처리에 중점을 두고 설계되었습니다. 빠른 속도와 효율성을 갖는 특징이 있기 때문에 위 이미지는 장당 약 0.6초 정도의 속도로 저장되었습니다. 그럼에도 불구하고 대량의 데이터, 예를 들어 20,000장을 저장한다고 했을 때는 약3.3시간(20,000*0.6 = 12,000sec)이 소요됩니다. 시간을 측정해보고나니 세 쇼핑몰을 전부 크롤링 하려면 속도 개선을 위한 또다른 방법이 필요하다고 생각했습니다.
그럼 다음 게시글에서는 속도 개선을 위해 어떤 방법을 사용했는지에 대해서 정리해보도록 하겠습니다. 긴 글 읽어주셔서 감사합니다! 😸
https://github.com/f-lab-edu/JBLY
GitHub - f-lab-edu/JBLY: [성능 40배 튜닝] 크롤링을 이용한 쇼핑몰 모아보기 서비스
[성능 40배 튜닝] 크롤링을 이용한 쇼핑몰 모아보기 서비스. Contribute to f-lab-edu/JBLY development by creating an account on GitHub.
github.com
| 참고 |
컴퓨터의 눈, Open CV 란?
OpenCV (Open Source Computer Vision Library) 실시간 컴퓨터 비전을 목적으로 한 프로그래밍 Library 이다. 실시간 이미지 프로세싱에 중점을 둔 라이브러리이다. 인텔 CPU에서 사용되는 경우 속도의 향상으
onnons.tistory.com
https://ballentain.tistory.com/50
이미지 읽는 방법 / cv.imdecode( ), io.BytesIO( )
이미지를 읽는 방법에는 여러가지가 있다. OpenCV를 사용해서 읽는 방법도 있고, PIL를 이용해서 읽는 방법도 있다. 그리고 최근에는 이미지 파일을 Binary 형태로 읽은 다음 ( = byte 단위로 읽는다는
ballentain.tistory.com
OpenCV: OpenCV modules
OpenCV 4.7.0-dev Open Source Computer Vision
docs.opencv.org
'파이썬' 카테고리의 다른 글
| [Discord/Python] Discord 봇으로 스레드 생성하기 (0) | 2023.08.12 |
|---|---|
| [Python병렬처리] Windows 환경에 Ray설치하기! (0) | 2023.04.17 |
| [Python Crawling] 셀레니움을 이용한 동적 크롤링, 잘 알고 쓰시나요? (2) | 2023.03.11 |


